








ユーソナーが解決する課題
-
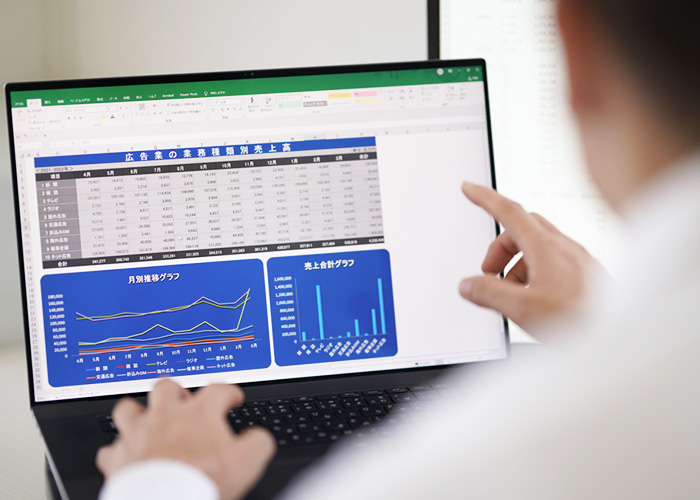
1.顧客データが散在
各部署で使うツール毎に取引先情報が分散しており、連携していない
-
2.重複データ解消が困難
重複登録された企業データの整備に膨大な時間がかかる
-
3.顧客毎の情報集約ができていない
会社全体での1社毎の繋がり、正確な取引量の把握が難しい

![]() 活用方法
活用方法
1.顧客データが散在
各部署で使うツール毎に取引先情報が分散しており、連携していない
2.重複データ解消が困難
重複登録された企業データの整備に膨大な時間がかかる
3.顧客毎の情報集約ができていない
会社全体での1社毎の繋がり、正確な取引量の把握が難しい
課題顧客データの散在
課題重複データ解消が困難

課題顧客毎の情報集約ができていない
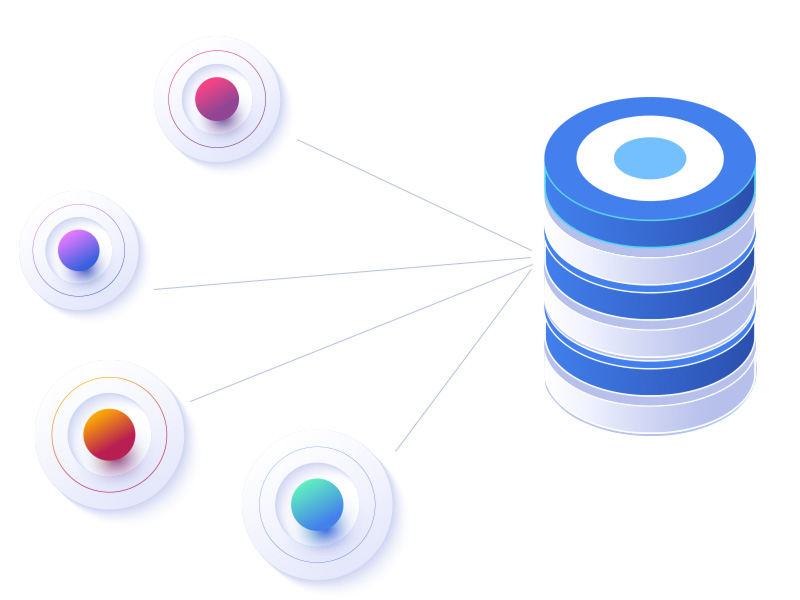
企業データベースLBCを辞書として活用し、高精度な名寄せ、クレンジング、情報付与を実現
ユーソナーに搭載する法人企業データベースLBCを辞書とするとこにより、法人顧客やリードデータを高精度にクレンジング、名寄せします。また、保有していない項目の補完や古いデータの更新が可能です。

高精度な名寄せにより、企業を正確にとらえることが可能
同一拠点のものや、住所移転、本社・支社などの関係をLBCに設けられているコードにより紐付け、正規化します。
横スクロールできます。

各種マスターを利用し、旧情報でも高いマッチング精度を実現
法人企業の社名変更情報や市町村統合情報などの情報をはじめ、書式統合マスターも保有。 これにより高い精度の名寄せが実現できます。
横スクロールできます。





ダウンロードできます
サービスやイベントに関する情報の受け取りはいつでも停止することができます。当社規定に関しては、「プライバシーステートメント」をご確認ください。

PURPOSE『目的別』活用方法
DEPARTMENT『部門別』活用方法
受注確率が高く、かつ未開拓なターゲットを
効率的に抽出し可視化。

ユーソナーは業種・業界問わず
様々な企業において活用いただいております。






